

@Prayer님 : 모분산을 추정할 때 n-1로 나누어야 하는 이유에 대한 답변입니다.
게시글 주소: https://image.orbi.kr/0001696165
왜 n으로 나누는 것이 타당하지 않은지를 살펴보자면….
모평균을 모르는 상태에서는 모평균을 표본평균으로 대체하여 사용해야 합니다. 그런데 이 과정에서 전체 분산의 일부가
표본평균에 흡수됩니다. 그래서 표본평균 자체를 모평균에 대한 추정값으로 사용하는 경우, 모분산을 추정할 때 그냥 n으로 나누게
되면 모분산보다 항상 작은 값이 추정되는 현상, 즉 편중(bias)이 발생하게 됩니다! 그 효과를 제거하기 위하여 n 대신 n-1
로 나누는 것입니다. 이를 베셀 보정(Bessel's correction)이라고 부릅니다.
실제로 유도해봅시다. 모분포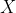 의 모평균이
의 모평균이  이고 모분산이
이고 모분산이  이라고 합시다.
이라고 합시다.
(여기서, 기대값을 나타내는 기호인 E를 두 줄이 들어간 굵은 글씨로 표기하여 눈에 확 들어오도록 차별화(?)를 이루었습니다. 사실 국제적인 표기법이기도 하고요.)
그리고 이 모분포의 크기가 n인 표본을 생각하고, 그 표본평균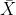 를 생각합시다. 그러면 의 평균은
를 생각합시다. 그러면 의 평균은  이고 분산은
이고 분산은  입니다.
입니다.
자, 그런데 잘 생각해봅시다. 모평균을 안다는 것은 이미 전체 집단에 대한 분포를 알고 있다는 것입니다. 그러나 우리가
현실에서 앙케이트 조사를 하거나 대선 후보에 대한 정보를 수집하는 등의 활동을 할 때에 모든 국민들을 상대로 결과를 얻어낼 수는
없습니다. (돈! 시간! 비협조! 주택총조사도 그래서 매년 못 하죠 -.-) 그러므로 우리는 항상 제한된 표본 내에서, 그 표본의 표본평균 자체를
모평균에 대한 추정값으로 삼고 계산을 진행할 수밖에 없습니다. 즉, n개의 샘플 에 대하여, 원래대로라면
에 대하여, 원래대로라면
우리는

의 값을 모분산에 대한 추정값으로 사용하려고 할 것입니다. 그렇다면 위 분포의 평균이 모분산과 일치할까요? 우선 계산의 편의를 위하여 다음 식을 먼저 보입시다.

증명은 다음과 같습니다.

단, 여기서 세번째 줄에서 네번째 줄로 넘어갈 때 i ≠ k 이면 두 분포가 독립임을 이용하여 기대값을 각각 취하였습니다. 그러면 식 (1)로부터

입니다. 보시다시피 이 경우 모분산보다 항상 작게 추정됨을 알 수 있습니다. 또한 위의 식으로부터, 표본평균 자체의 분산이 이러한 현상의 직접적인 원인임을 알 수 있습니다. 따라서

를 고려하여야 원하는대로 을 얻습니다.
을 얻습니다.
모평균을 모르는 상태에서는 모평균을 표본평균으로 대체하여 사용해야 합니다. 그런데 이 과정에서 전체 분산의 일부가
표본평균에 흡수됩니다. 그래서 표본평균 자체를 모평균에 대한 추정값으로 사용하는 경우, 모분산을 추정할 때 그냥 n으로 나누게
되면 모분산보다 항상 작은 값이 추정되는 현상, 즉 편중(bias)이 발생하게 됩니다! 그 효과를 제거하기 위하여 n 대신 n-1
로 나누는 것입니다. 이를 베셀 보정(Bessel's correction)이라고 부릅니다.
실제로 유도해봅시다. 모분포
(여기서, 기대값을 나타내는 기호인 E를 두 줄이 들어간 굵은 글씨로 표기하여 눈에 확 들어오도록 차별화(?)를 이루었습니다. 사실 국제적인 표기법이기도 하고요.)
그리고 이 모분포의 크기가 n인 표본을 생각하고, 그 표본평균
자, 그런데 잘 생각해봅시다. 모평균을 안다는 것은 이미 전체 집단에 대한 분포를 알고 있다는 것입니다. 그러나 우리가
현실에서 앙케이트 조사를 하거나 대선 후보에 대한 정보를 수집하는 등의 활동을 할 때에 모든 국민들을 상대로 결과를 얻어낼 수는
없습니다. (돈! 시간! 비협조! 주택총조사도 그래서 매년 못 하죠 -.-) 그러므로 우리는 항상 제한된 표본 내에서, 그 표본의 표본평균 자체를
모평균에 대한 추정값으로 삼고 계산을 진행할 수밖에 없습니다. 즉, n개의 샘플
우리는
의 값을 모분산에 대한 추정값으로 사용하려고 할 것입니다. 그렇다면 위 분포의 평균이 모분산과 일치할까요? 우선 계산의 편의를 위하여 다음 식을 먼저 보입시다.
증명은 다음과 같습니다.
단, 여기서 세번째 줄에서 네번째 줄로 넘어갈 때 i ≠ k 이면 두 분포가 독립임을 이용하여 기대값을 각각 취하였습니다. 그러면 식 (1)로부터
입니다. 보시다시피 이 경우 모분산보다 항상 작게 추정됨을 알 수 있습니다. 또한 위의 식으로부터, 표본평균 자체의 분산이 이러한 현상의 직접적인 원인임을 알 수 있습니다. 따라서
를 고려하여야 원하는대로
0 XDK (+0)
유익한 글을 읽었다면 작성자에게 XDK를 선물하세요.















대략적으로는 알고 있었는데, 이렇게 되는 것이로군요. 좋은 글 감사합니다!
ㅇ ㅏ ㅇ ㅏ 굳입니다 ~